Extracting Text and Data with Amazon Textract
- 03.07.2021
- 97
Eduardo Freitas | Duration: 1h 20m | Video: H264 1280x720 | Audio: AAC 48 kHz 2ch | 165 MB | Language: English + SUB
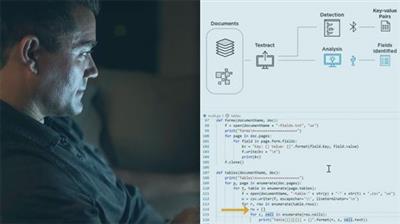
This course will teach you how to use and work with Amazon Textract, which extracts text and data from scanned documents, going beyond traditional OCR.
Businesses are moving to an instantaneous and digital world, but we will still need physical documents for quite some time. In this course, Extracting Text and Data with Amazon Textract, you will learn to use OCR technology to extract text, and key-value pairs of data from scanned documents. First, you will explore how to detect printed text and numbers in a scan or rendering of a document. Next, you will discover how to detect key-value pairs in document images automatically so that they can retain the inherent context of the document without any manual intervention. Finally, you will learn how to preserve the composition of data stored in tables during extraction. When finished with this course, you will have the skills and knowledge of how to use Amazon Textract to create smart search indexes, build automated approval workflows, and better maintain compliance with document archival rules by flagging data that may require manual input, as well as being able to export data contained within those documents to other systems.
Download link:
rapidgator_net:
https://rapidgator.net/file/05edefad04f29619d3cd34e68b0e1aa3/775j1.Extracting.Text.and.Data.with.Amazon.Textract.rar.html
uploadgig_com:
https://uploadgig.com/file/download/4e88b85b72336073/775j1.Extracting.Text.and.Data.with.Amazon.Textract.rar
nitroflare_com:
https://nitro.download/view/4411A95633D7746/775j1.Extracting.Text.and.Data.with.Amazon.Textract.rar
https://rapidgator.net/file/05edefad04f29619d3cd34e68b0e1aa3/775j1.Extracting.Text.and.Data.with.Amazon.Textract.rar.html
uploadgig_com:
https://uploadgig.com/file/download/4e88b85b72336073/775j1.Extracting.Text.and.Data.with.Amazon.Textract.rar
nitroflare_com:
https://nitro.download/view/4411A95633D7746/775j1.Extracting.Text.and.Data.with.Amazon.Textract.rar
Links are Interchangeable - No Password - Single Extraction